The Map Room
When you write code in an editor, you’re doing two things at once. You’re writing instructions for the computer, and you’re reading the system — seeing what’s there, understanding the shape of it, building a mental model. The writing and reading happen together, continuously, each informing the other. It’s not just a nice workflow. It’s continuous feedback. It’s how you stay calibrated to reality.
AI breaks this.
With AI-assisted development, you write a prompt, and the AI writes the code. Then you read what it wrote. The writing and the reading are now separate activities. Speed increases — dramatically — but at the cost of knowledge. You no longer know what your system looks like, because you weren’t there when it changed. The feedback loop between reading and writing is now discontinuous.1
So what do we do about it?
“Just Do Code Review”
The obvious answer is: review the AI’s output. Read the diff. Check what it did.
We already know this doesn’t work.
SmartBear’s study of code review practices at Cisco found that review effectiveness drops sharply beyond 200-400 lines of code.2 Anyone who has ever done code review already knows this in their bones. After a certain size, you’re not reviewing — you’re scrolling. Your eyes glaze. You start looking for patterns you recognise rather than actually understanding what changed. Large diffs are treated like the Apple Terms and Conditions: scrolled past and accepted.
AI-generated diffs will be enormous. They already are. And they’ll only get bigger as the models improve and people trust them with larger changes. “Just review it” is not a strategy. It’s a prayer.
In XP we avoid code review entirely — that’s what pair programming is for. The continuous peer feedback of pairing replaces the discontinuous batch review of a pull request. But pairing doesn’t help here either. You can’t pair with an AI in the same way. You’re not sharing a mental model in real time; you’re issuing an instruction and inspecting the result. The feedback is still discontinuous.
The Problem of Ignorance
This is a problem of ignorance — we don’t know what the AI did, and we need to find out. The standard Agile strategy applies: make small changes, learn from them. People are already doing this. Experienced developers prompt for small, focused changes and check the result before moving on, rather than letting the AI rip through the whole codebase. Good instinct.
But we can do better. Reading changes in code is slow and inefficient — it’s a high-friction way of updating your mental model. We need better ways to visualise changes, both proposed and after the fact, to reduce the friction of integrating them back into our own minds. Which is, of course, the only integration that actually matters.
The Map Room
The military distinguishes three levels of operations: tactical, operational, and strategic.3 Tactical is the individual engagement — squads, buildings, firefights. Operational is the campaign — coordinating forces across a theatre. Strategic is the war — national objectives, resource allocation, the shape of the whole conflict.
When you write code in an editor, you have a tactical view. You can see every function, every variable, every line. The operational and strategic views — the architecture, the relationships between components, the shape of the system — you keep in your head. Sometimes in the docs, but rarely, and never up to date.
If AI is pushing us up a level of abstraction — and I think it is, though I’ll accept arguments — then we need to equip ourselves with an operational view. We need a map room.
Or better: a Combat Information Centre. The CIC on a warship takes raw data from radar, sonar, radio — sources no commander could monitor directly — and organises it into a form the commanding officer can actually use.4 The captain doesn’t stare at the radar screen. The CIC watches the radar, plots the contacts, and presents the tactical picture. The captain makes decisions based on that picture.
Right now we’re captains staring at the radar. We can always “go to the front” and read the code to find out what’s happening, but this is exactly the inefficient, high-friction feedback we’re trying to avoid. We need a CIC — something that takes the raw output of the AI and organises it into a form more convenient and usable by the developer in authority.
Prompting Is Not Code
I keep hearing that “prompting is the new programming.” It isn’t.
Code is a unique medium. It’s simultaneously an instruction to the computer and a visualisation of the system’s behaviour. You read it and you know what it does — or at least, you can know, if the code is any good. Abelson and Sussman put it well: “Programs must be written for people to read, and only incidentally for machines to execute.”5
A prompt is just an instruction. It tells the AI what to do. It does not show you the state of the system. It does not represent the system’s structure. It’s not a map — it’s an order barked into a field telephone. You can’t look at a prompt and understand what your system does, any more than you can look at a general’s orders and understand the state of the battlefield.
We need the map.
The UML Irony
Here’s the irony. In the early 2000s, the Object Management Group pushed Model Driven Architecture — the idea that you could draw UML diagrams and generate code from them automatically.6 No more developers! Just draw the boxes and arrows. Martin Fowler called it “Night of the Living CASE Tools” and was, characteristically, right.7
The dream was diagrams-to-code. It failed, because it misunderstood what’s hard about software development.
But what if we reversed it? What if, instead of generating code from diagrams, we generated diagrams from code?
C4 diagrams, sequence diagrams, component diagrams — generated from the codebase, kept up to date by the AI. Not as a replacement for code, but as the operational view that lets you see what the AI has done to your system. Simon Brown’s C4 model already gives us a vocabulary for this: system context, containers, components, code.8 Four levels of zoom on the same system. The map room at different scales.
The 90s dream of diagrams replacing developers was wrong. But diagrams for developers — that’s the ticket.
Monster Wargames
If you’ve never played a hex-and-counter wargame, bear with me. They’re maps divided into hexagonal spaces, with little cardboard counters representing military units. You push the counters around according to rules that simulate combat, supply, movement. They exist at every level of abstraction. Squad Leader models individual squads and single buildings. Battle for Germany models entire fronts and army groups.
The problem comes with what the hobby calls “monster” wargames — games that use one level of abstraction at a scale where another would be more appropriate.
Campaign for North Africa (SPI, 1979) has over 1,600 counters and tracks individual water rations for Italian troops. It is estimated to take 1,500 hours to complete. The ambition is strategic — the whole North African campaign — but the resolution is tactical. You’re drowning in detail you can’t synthesise.
War in Europe (SPI, 1976) simulates all of World War II in Europe at divisional level across nine maps covering 38.5 square feet. Strategic scope, tactical resolution. Four thousand counters. Four folding tables, minimum.
 War in Europe (SPI, 1976) — 4,000 counters across nine maps. (source)
War in Europe (SPI, 1976) — 4,000 counters across nine maps. (source)
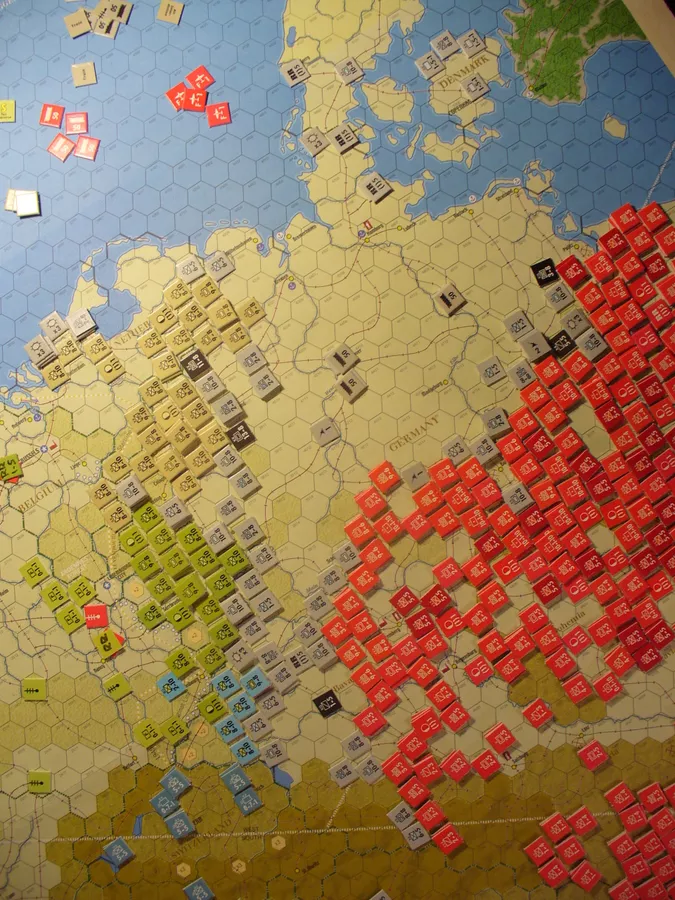 Zoomed in: the Soviets invade Germany. Every division has its own counter. Can you tell what’s happening? (source)
Zoomed in: the Soviets invade Germany. Every division has its own counter. Can you tell what’s happening? (source)
Now compare Battle for Germany (SPI, 1975). Same theatre. Same war. But at the right level of abstraction. Armies, not divisions. Fronts, not individual hexes. You can see what’s happening.
 Battle for Germany (SPI, 1975) — the same theatre, at the right level of abstraction. You can see the front lines. (source)
Battle for Germany (SPI, 1975) — the same theatre, at the right level of abstraction. You can see the front lines. (source)
 Zoomed in: the Eastern Front. Armies, fronts, pressure — the shape of the situation is visible. (source)
Zoomed in: the Eastern Front. Armies, fronts, pressure — the shape of the situation is visible. (source)
The monster wargame is reading the AI’s diff. Thousands of counters on a vast map, unreadable to anyone who hasn’t been staring at it for hours. The strategic game is the operational view we need — the same system, but at a level of abstraction where the shape of the change is visible.
Code is Squad Leader. You can see every squad, every building. That’s fine when you’re the one pushing the counters. But when the AI is generating whole features, you need Battle for Germany. You need to see the front lines, not count individual units.
The Smalltalk Renaissance
There’s a tradition in software that already knows how to do this. Object-oriented programming — real OO, not the enterprise Java parody — was always about objects communicating through messages, and about making those communication patterns visible.
Alan Kay, who coined the term “object-oriented,” was explicit that the key idea was messaging, not objects.9 And Smalltalk, the language that embodied this vision, came with an entire environment for visualising the system: browsers, inspectors, workspaces. You didn’t just write Smalltalk — you inhabited it. The system was its own map.
Beck and Cunningham’s CRC cards took this further — Class, Responsibility, Collaborator cards that let you physically model object interactions before writing any code.10 Physical visualisation of software structure. In 1989.
Today, Tudor Girba’s Glamorous Toolkit is taking this tradition to its logical conclusion with what he calls “moldable development” — the idea that your development environment should be mouldable to show you what you need to see, when you need to see it.11 Not a fixed set of views, but views that adapt to the code. The system explains itself.
This is exactly the kind of thinking we need. Not “how do I read more code faster” but “how do I build views of the system that show me what matters at the right level of abstraction?”
Back to the Map Room
AI-assisted development creates discontinuous feedback at the tactical level. The reading and writing of code are decoupled. The fix isn’t just smaller prompts, though that helps — it’s the same instinct as making smaller commits, and it works for the same reason.
But the real fix is changing the medium of feedback. Stop trying to maintain continuous feedback by reading code — that’s fighting on the AI’s terms, at a level of abstraction where you’ll always be outpaced. Instead, build continuous feedback at the operational and strategic levels. Get the AI to generate the maps. C4 diagrams, sequence diagrams, dependency graphs, component interaction views — whatever makes the shape of the change visible at a glance.
We’re in the map room now. We’d better make sure the maps are good.
- I’ve written about this more fully in Continuous Feedback Distributes Surprise. The short version: continuous feedback distributes surprise across many small moments. Discontinuous feedback concentrates it into crises. AI-assisted development, unless we’re careful, concentrates surprise.
- Jason Cohen, “Best Kept Secrets of Peer Code Review,” SmartBear Software (2006). The study analysed 2,500 code reviews at Cisco Systems. The finding that review effectiveness drops sharply beyond 200-400 LOC has been widely cited, including in SmartBear’s later “Best Practices for Code Review” guide.
- This three-level framework was first articulated by Aleksandr Svechin in Strategy (1926) and has since become doctrine. See US Joint Chiefs of Staff, JP 3-0: Joint Operations, for the modern formulation.
- “Regardless of the vessel or command locus, each CIC organizes and processes information into a form more convenient and usable by the commander in authority.” See Combat Information Center, Wikipedia.
- Harold Abelson and Gerald Jay Sussman, Structure and Interpretation of Computer Programs (MIT Press, 1985), preface. I’m happy to argue about this if you think they’re wrong.
- Object Management Group, “MDA Guide Version 1.0.1,” 2003. The original MDA specification was adopted in 2001. The dream: platform-independent models transformed automatically into platform-specific code.
- Martin Fowler, “Model Driven Architecture,” MartinFowler.com, 2004. Fowler’s critique was that MDA repeated the mistakes of CASE tools from the late 1980s — assuming that the hard part of software was typing it in, rather than figuring out what to type.
- Simon Brown, “The C4 model for visualising software architecture,” c4model.com. Brown’s model is explicitly designed to provide views at different levels of abstraction — exactly the problem we’re facing.
- Alan Kay, “The Early History of Smalltalk,” ACM SIGPLAN Notices 28(3), March 1993. Kay has said repeatedly that he regrets coining the term “object-oriented” because people focus on the objects rather than the messages between them. “The big idea is messaging.”
- Kent Beck and Ward Cunningham, “A Laboratory for Teaching Object-Oriented Thinking,” OOPSLA ‘89 Proceedings. CRC cards are deliberately low-fidelity — index cards, handwritten — because the point is rapid physical modelling of relationships, not precision.
- Tudor Girba, “Moldable Development,” gtoolkit.com. Glamorous Toolkit builds on the Pharo Smalltalk tradition, extending it with custom inspectors, views, and analyses that developers build for their specific codebase.